
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- database
- priorityqueue
- 시뮬레이션
- EventScheduler
- MVC
- wrapper class
- ACID
- spark
- SQL
- hdfs
- ES6
- 우선순위큐
- BFS
- bigdata
- Spring
- 프로그래머스
- Parquet
- 구현
- S3
- Transaction
- MySQL
- boto3
- namenode
- BIT연산
- datanode
- Algorithm
- procedure
- 백준
- greedy
- JPA
- Today
- Total
IT 개발일지
[Apache Parquet] Parquet 알아보기 본문

1. Apache Parquet
- 대량의 데이터를 효율적으로 저장하는 방식 중 하나, 하둡 생태계에서 많이 사용되는 파일 포맷
- 열 지향 저장 방식
1. Parquet 특징
- 적은 오버헤드만으로도 중첩 데이터(nested data)를 효율적으로 저장할 수 있음
- 열 기반으로 저장하기 때문에 특정 열만 저장하는 쿼리의 경우 전체 데이터를 읽지 않아도 된다.
- 같은 열에 동일한 타입의 데이터가 많기 때문에, Snappy, gzip, LZO 등 다양한 압축 알고리즘을 사용할 수 있다.
- 스키마 기반 저장을 하여 데이터의 구조를 명확히 할 수 있다
- 대용량 데이터에 대한 배치 처리에 적합하며, Spark, Hive, Presto 등과 같은 데이터 처리 엔진과의 통합 용이하다.
2. Parquet 데이터 타입
- Parquet은 크게 primitive type과 Logical type으로 나뉘는데, String은 logical type이다.
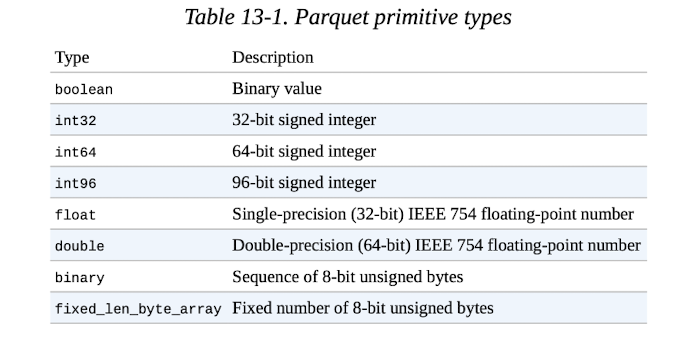

3. Parquet 장,단점
- 장점
1. 효율적인 I/O: 열 단위로 데이터를 읽기 때문에 특정 열에 대한 질의가 많을 때 I/O 비용을 할 수 있다. 전체 데이터를 로드할 필요 없이 필요한 열만 선택적으로 로드 가능하기 때문이다.
2. 높은 압축률: Parquet는 열 단위로 데이터를 압축하기 때문에, 반복되는 데이터 패턴을 잘 압축할 수 있어 데이터 크기가 크게 줄어들어 저장 공간을 절약할 수 있다.
3. 분산 시스템과의 통합: Hadoop, Spark, Hive, Impala 등 분산 처리 시스템에서 Parquet를 네이티브로 지원하기 때문에 대용량 데이터를 병렬 처리하는 데 매우 적합하다.
4. 성능 향상: 컬럼 기반 저장과 압축을 통해, 데이터 스캔 및 집계 쿼리 성능이 매우 뛰어나서. 분석 작업에서 빠른 속도를 보장할 ㅜ수 있다.
- 단점
1. 쓰기 성능: write cost가 크기 때문에 데이터를 열 단위로 변환하고 압축하기 때문에 실시간 쓰기보다는 배치 처리에 적합해서 실시간으로 쓰는 작업에는 적합하지 않다.
2. 작은 파일 처리 비효율: 작은 파일이 많을 경우 오버헤드가 발생하여 비효율적일 수 있다. HDFS와 같은 경우는 block-size보다 작은 데이터들을 저장할 때에는 Namenode에 많은 메타데이터가 존재하며 성능 저하가 발생하는데, 이때 병렬 처리가 비효율적으로 이루어지는 등 오버헤드가 발생한다.
3. 복잡한 스키마 관리: 스키마가 고정되어 있기 때문에, 데이터 스키마가 자주 변경되거나 다양한 스키마의 데이터를 처리해야 하는 경우 관리가 복잡해질 수 있다.
4. 랜덤 액세스에 부적합: 열 기반으로 저장되는 특징으로 인해 행 단위의 데이터에 빠르게 접근해야 하는 경우 성능이 떨어질 수 있다. 그래서 랜덤 액세스보다는 분석 쿼리에 더 적합하다.
즉 랜덤 엑세스는 다음과 같이 특정 행(row)에 접근해서 데이터를 조회하는 방식이고
SELECT * FROM customers WHERE customer_id = 12345;
분석 쿼리와 같은 경우는 대량의 데이터 집계하거나, 특정 조건에 맞는 데이터를 필터링하는 쿼리를 말한다.
즉, 다음 예시와 같이 특정 기간에 해당하여 쿼리를 계산하는 등 필터링을 할 때 유리하다고 할 수 있다.
SELECT AVG(sales) FROM sales_data WHERE date BETWEEN '2024-01-01' AND '2024-12-31';
2. Partitioning & Bucketing
큰 데이터셋에서 query performance를 증가시킬 수 있는 강력한 도구
1. Partitioning
- Apache parquet에서는 기본적으로 partitioning을 한개 이상의 column을 기준으로 데이터를 sub-directory에 나누어서 저장하낟.
- 각각의 디렉토리는 partitining column의 distinct value가 된다.
- 다음 예시는 year과 month를 기준으로 partitioning한 것을 나타낸다.
/sales/year=2023/month=01/
/sales/year=2023/month=02/
...
- 파티셔닝의 장점
1. Data pruning : pruning은 가지치기라는 의미인데, 말 그대로 partitioning한 column을 기준으로 쿼리 필터를 진행하면 전체 디렉토리를 스캔할 필요 없이 사전에 조건에 맞는 디렉토리만 읽기 대상에 선택하게 되어 쿼리 향상에 도움을 준다.
2. Reduced I/O : 그에 따라 자연스럽게 디스크에서 가져오는 데이터 양을 최소화해 I/O오버헤드를 줄일 수 있다.
3. Organized Data : 데이터가 더 조직적으로 되어 향후 데이터 관리를 할 때 용이하거나, 특정한 데이터 대상으로 쿼리를 할 때 유용하다.
2. Bucketing
- 특정 column을 기준으로 데이터를 해시 값을 사용해, 고정된 수의 버킷(bucket)으로 나누어 저장한다.
- partitioning이 디렉토리 기준으로 데이터를 나눈다면, bucketing은 같은 파티션 내에서 데이터를 고정된 수의 파일로 나누는 것을 의미한다.
- 다음 예시는 앞의 partitioning 예시에서 customer_id를 기준으로 버킷으로 나누는 것이다.
- 데이터는 customer_id의 해시 값에 따라 각 버킷에 분산되는 것을 확인할 수 있다.
/sales/year=2023/month=01/bucket_00001
/sales/year=2023/month=01/bucket_00002
/sales/year=2023/month=01/bucket_00003
...
/sales/year=2023/month=01/bucket_00010
- bucketing의 장점
1. JOIN 및 GROUP BY 성능 향상: 위의 예시에 따르면 customer_id로 JOIN을 하거나 그룹화할 때, 동일한 버킷끼리만 연산하면 되므로 처리 범위가 줄어들고 성능이 좋아진다.
2. 균등한 데이터 분산: 버킷 수를 적절히 설정하면 데이터를 균등하게 분산시킬 수 있어 병렬 처리를 최적화할 수 있다.
출처
- https://learncsdesigns.medium.com/understanding-apache-parquet-d722645cfe74